Making user-owned AI a reality
.png&w=3840&q=75)
TLDR:
- Inference × DAWN Partnership: We're partnering with Inference.net to bring decentralized AI to DAWN nodes, empowering consumers to seamlessly participate in the AI economy.
- Problem: AI inference currently runs primarily in centralized mega-datacenters, making the barrier to entry too high for everyday people—but emerging opportunities like batch inference open a new door for consumers to capitalize.
- Inference’s Unique Value: Inference.net provides a decentralized inference framework with custom, optimized AI models that thrive in cost-sensitive, batch inference environments, efficiently leveraging widely available consumer-grade GPUs to allow consumers to participate in building a user-owned AI future.
The people are building a new Internet—one household, and one Black Box at a time. As a decentralized Internet moves from possibility to inevitability, certain core technologies and protocols emerge as essential foundations of this landscape. In this series, we explore these history-defining protocols, highlighting their unique roles in enabling a consumer-owned digital, why each is indispensable, and how the Black Box is designed specifically to bring their benefits directly to households.
The Black Box isn’t just a WiFi router—it offers a practical glimpse into a people-powered AI future. Instead of AI running exclusively in distant mega-datacenters owned by corporations extracting value from your data, this is a future where AI runs directly in your home, secures your data, and provides you immense value in return. Rather than letting big companies quietly capture the economic benefits from artificial intelligence, decentralized AI ensures your household directly benefits from the transformative wealth and innovation that AI will create.
Inference: The Engine of the Intelligence Age
At the heart of this transformative future lies a critical engine: inference. Like the combustion engine that powered the industrial revolution, inference is the mechanism that will power the Intelligence Age. AI models produce their results through inference, a compute intensive process. In a future where AI models will generate immense economic value, controlling inference means controlling the distribution of that value—and deciding who ultimately benefits from artificial intelligence.
Historically, control over inference has been strictly limited to massive corporations operating enormous data centers filled with specialized, cutting-edge hardware—like Nvidia’s H200 GPUs—that cost tens of thousands of dollars each. This astronomical cost makes it financially unrealistic for a typical consumer to participate meaningfully in modern AI-driven economic opportunities that cutting-edge models unlock. As a result, households have been relegated to passive roles, merely using services powered by centralized AI rather than benefiting directly from their immense value. But we are currently living through a profound technological transformation, and it's crucial that we challenge this status quo: we must create a pathway for everyday people to own and operate the inference infrastructure that will inarguably shape our future.
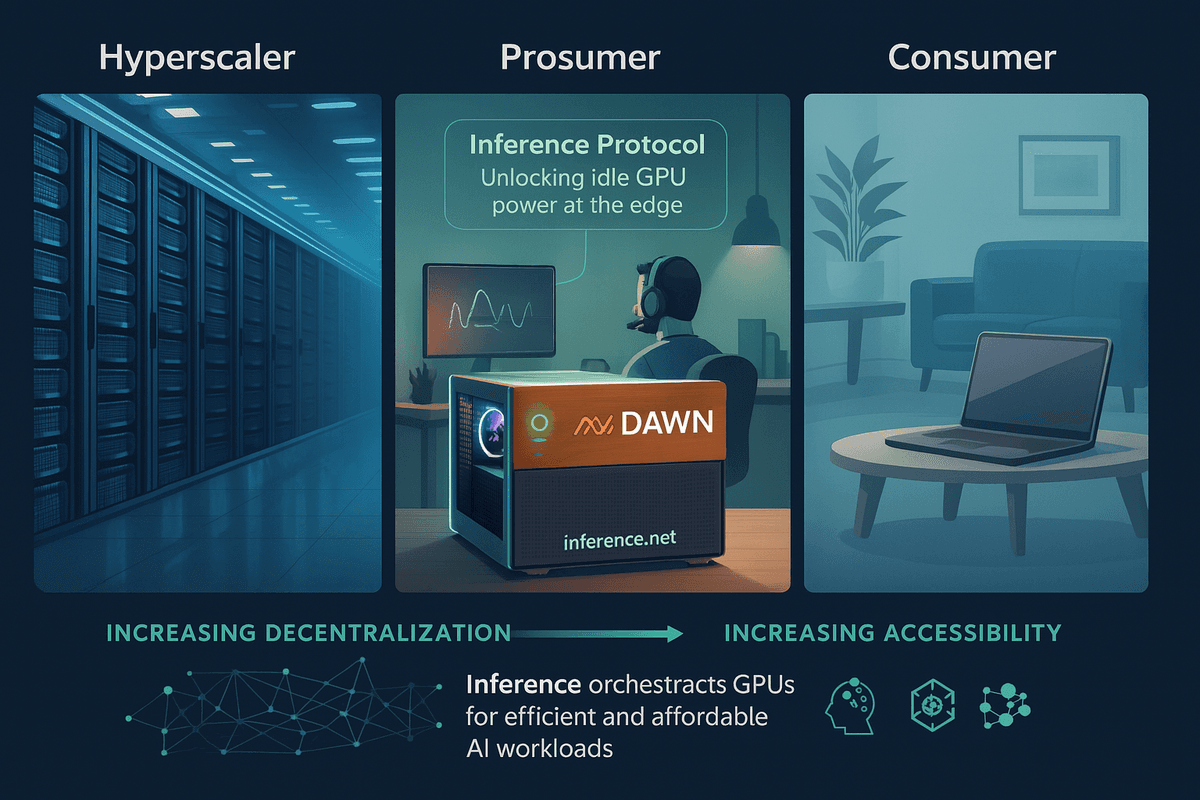
Consumer GPUs: Strength in Numbers
How can consumers realistically compete with hyperscalers deploying ultra-expensive GPUs at massive industrial scale? The answer is elegantly simple: we leverage strength in numbers, not individual power. Instead of depending on a few powerful clusters of prohibitively expensive GPUs, we must creatively unlock the vast potential embedded within millions of accessible consumer-grade and prosumer GPUs already widely available.
To effectively harness this strength in numbers, technology leaders have emerged, and one of the most promising is the aptly named protocol, Inference.net. Inference.net provides a decentralized protocol incentive layer as well as the critical orchestration capabilities needed to channel the collective power of numerous consumer GPUs—ensuring the whole becomes far greater than the mere sum of its parts.
Optimized Models for Everyday Hardware
Recognizing that competing directly against expensive, cutting-edge hardware isn't practical, Inference.net has pursued a different, smarter approach. They specialize in training custom AI models, designed specifically to achieve 95% of top-tier model performance while running efficiently on affordable consumer and prosumer GPUs, reducing costs by an order of magnitude. By understanding market dynamics and tailoring models to broad yet specific enterprise use-cases, Inference.net makes everyday hardware economically viable, effectively positioning households as formidable competitors to traditional hyperscalers.
Why Batch Inference Matters
Inference.net’s innovative approach fills us with conviction because their technology strategy aligns perfectly with what will be the biggest market in AI: batch inference. Unlike real-time inference tasks, which require immediate answers, batch inference involves AI workloads where instant responses aren’t necessary. When immediate turnaround isn’t required, why allocate costly, cutting-edge GPUs like Nvidia’s H200 to the task? Inference.net’s model optimization strategy ensures performance remains competitive and no longer acts as the bottleneck, shifting the main consideration to processing speed. But for batch inference tasks—where a rapid response isn't essential—speed is secondary, allowing workloads to run on far more economical hardware. In this scenario, no hardware footprint offers greater affordability and accessibility than that of the home.
Our belief that batch inference will dominate inference demand is for a simple reason: batch inference is fundamentally unbounded. Real-time inference, run by expensive GPUs due to their extreme speed, has an inherent upper limit—the number of humans on the planet requiring instantaneous responses (approximately eight billion). Batch inference, however, is asynchronous and can feed into countless downstream systems, automated processes, and large-scale computations, whose potential scale vastly surpasses the limited scope of human interactions. Demand for batch inference could easily scale to trillions of requests per day, dramatically eclipsing the constrained market for real-time interactions.
Inference.net × DAWN: Intelligence and Hardware Platform for Powering the Decentralized AI Revolution
Given the immense potential for batch inference and the financial efficiencies of consumer hardware, decentralized AI isn't just a promising idea—it’s an economic inevitability. The DAWN Black Box, equipped with GPUs offering up to 20GB of VRAM, is perfectly positioned to participate in demanding batch inference workloads. By pairing Inference’s optimized AI models with the Black Box’s accessible, high-performance hardware, every household can directly participate in a market traditionally owned by hyperscalers running expensive data-center clusters.
This demand signal (batch inference) and supply signal (optimized models) are why we view decentralized AI as an inevitability in the Internet of the future, and exactly why we're honored to have Inference as a founding Black Box partner. Together, Inference.net and DAWN represent the essential intelligence and hardware layers required to power a consumer-owned AI future. We’re thrilled to join them for the ride and help build an Internet where everyday people participate in, own, and directly benefit from the transformative economic value of AI.
Sam Hogan, Inference founder, said “empowering consumers all over the world to run AI models at home and resell unused GPU cycles back to the network enables a whole new class of infrastructure democratization that the world hasn’t seen before. Black Box is one big step in that direction.”